머신러닝 2
Machine Learning 2
classification : naive bayesian classifier
- Feature 결정
- 무엇을 자질로 사용할지 결정하는 것은 매우 어려운 문제이다.
- 학습 코퍼스 수집 -> Feature 벡터로 표현, 정답 레이블
- 학습(Training)
- 알고리즘 : naive bayesian classifier
- 적용 (Inference/Prediction)
결론적으로 Naive Bayesian Classifier는
매우 간단하며, 학습 속도가 빠르다.
그러나 성능은 별로이다.
Machine Learning 3
기계학습 분류
Supervised
- classification
- regression
unsupervised
- clustering
Supervised Learning
학습 데이터 : (input x, output y)
대표적 알고리즘들
- Naive Bayes
- Decision Trees
- K-Nearest neighbor
- Linear Models
- Support Vector Machines(SVM)
- Multi Layer Perceptron (MLP)
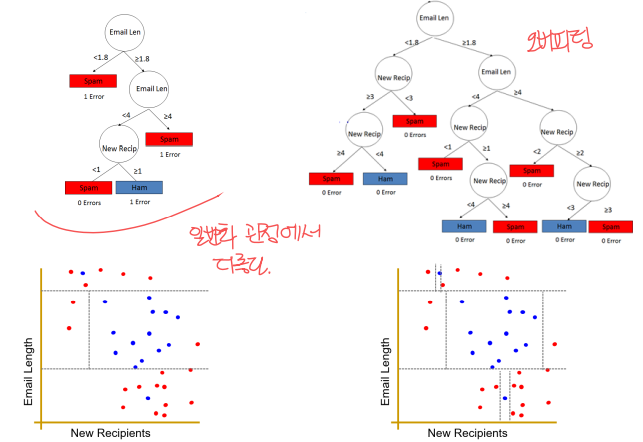
Decision Tree
결정 트리
Tree structure
internal node -> feature에 대한 질문
- branch -> 질문 결과에 따라 갈라짐
lead nodes -> class labels
어떤 것이 더 좋은 Decision Tree일까??
K-Nearest Neighbors
입력데이터에 가장 가까운 k개 데이터의 레이블을 표결하여 출력 클래스를 결정한다.
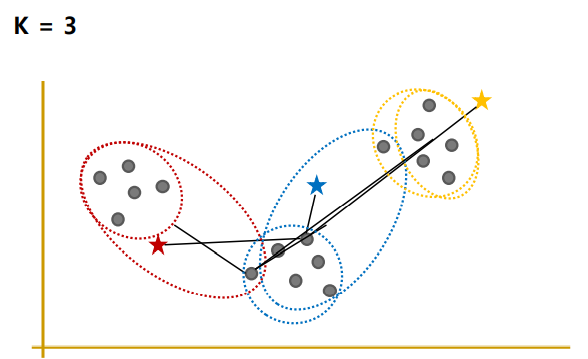
예를들면, k=3인 경우
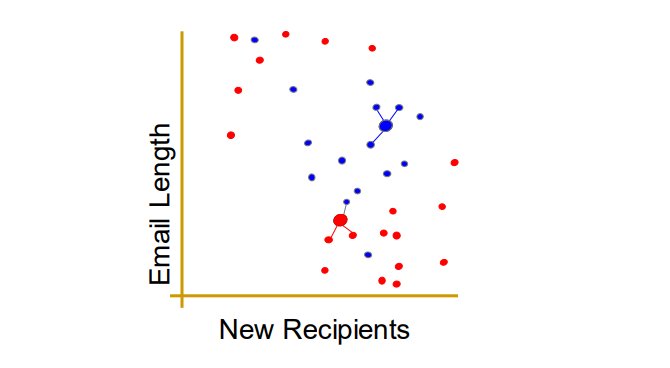
입력데이터에 가장 가까운 k개 데이터의 레이블을 표결하여 출력 클래스를 결정한다.
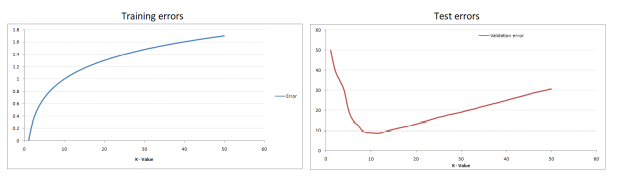
‘가장 가까운’을 알기위해 거리를 계산하여야 한다.
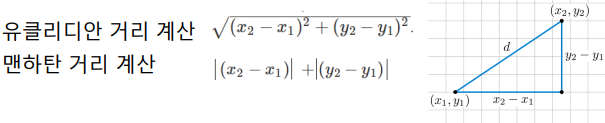
‘k개’ (이웃 개수 k개) : 가장 최고의 성능을 보이는 k를 결정하기 어렵다.
장/단점
- 학습단계의 불필요
- 적용단계의 예측이 느리다 : K개의 데이터와 거리계산을 해야하기 때문
Linear Models
직선을 그어서 문제를 해결해 보자 => y = ax+b
선형 모델
- Classification
- Binary Classifier (Logistic Regression)
- Softmax Classifier (Multinomial Logistic Regression)
- Regression
- 둘 모두에 적용이 가능하다
어떻게 W와 b를 결정할 것인가?
- 최대한 학습 데이터에 맞출 수 있도록
- H(x) - y

SVM
Support Vector Machine (SVM)
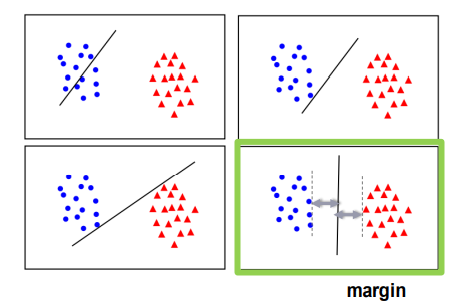
Maximum margin Lineat Classifier
두 클래스를 어떻게 나누는게 가장 좋을까?
=> margin이 최대한이 되는 직선으로 나누자!
Unsupervised Learning
학습 데이터 : (input x)
정답 y가 주어지지 않음
대표적 알고리즘들
- K-means Clustering
- Hierarchical Clustering
K-means Clustering
K개로 그룹화
예를들면
N-Nearest Neighbor과는 다른것 <- supervised learning
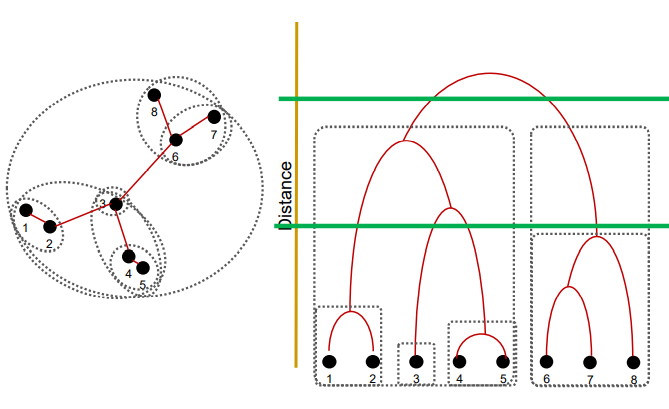
Hierarchical Clustering
두가지 방법
- 아래에서 위쪽으로 (bottom-up) 데이터를 그룹화
- 위에서 아래쪽으로 (top-down) 데이터를 그룹화