machine learning - 실습 4주차
k-Nearest Neighbors Classifier (k-NN)
k-NN 알고리즘 순서
- class label을 가진 학습 데이터 준비
- 새로운 test data가 들어옴 (class label이 없는)
- 모든 학습데이터와 test data의 거리를 계산
- 그중 k개의 nearest data를 선택
- k개의 이웃중 voting하여 결과를 선택
Data Loading -> Data Preprocessing -> Classification -> Evaluation
Data Loading
- 경로 설정 + 라이브러리 import
import os
import numpy as np
import pandas as pds
path = os.path.join('..','dataset','dataset_for_lab04.csv')
- 입력받아온 데이터를 확인 (1)
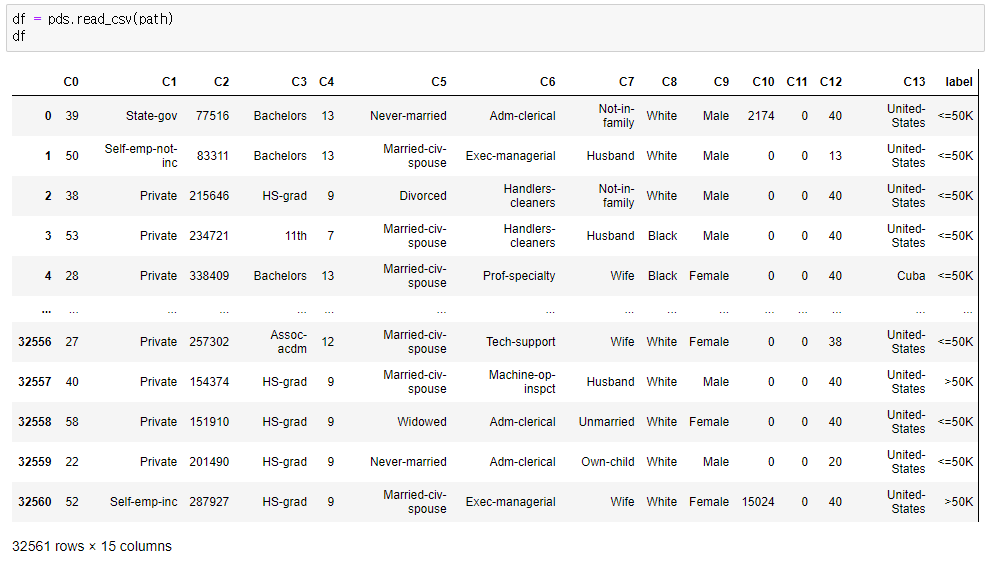
- 입력받아온 데이터를 확인 (2)
- 입력받아온 데이터를 확인 (3)
Data Preprocessing
-
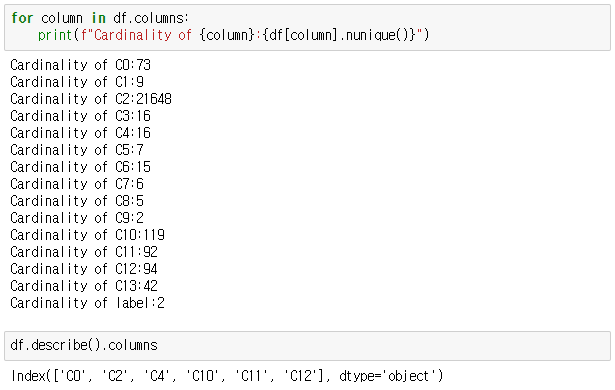
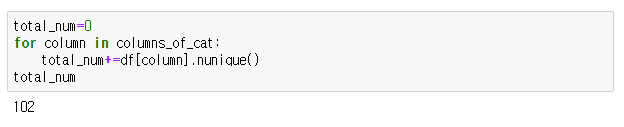
nunique()는 데이터에 column별 고유값의 개수를 출력해주는 함수이다.
- column별로 고유값의 개수를 확인한다.
- len(set)같은 의미, 중복을 제거한 개수를 세어준다.
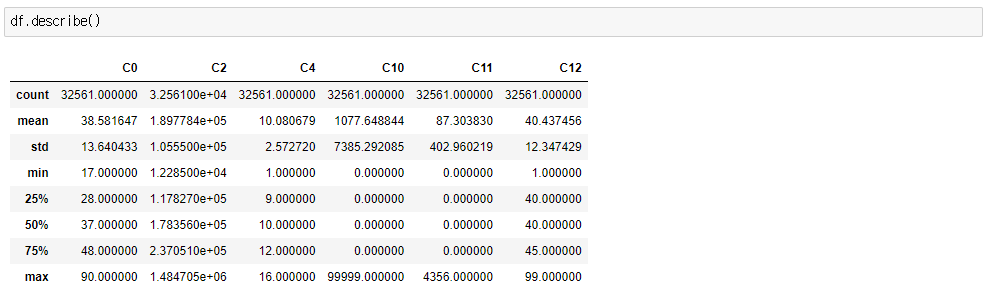
- 그리고 df의 colums중 숫자로 이루어진것은 describe()로 확인이 가능하다.
-
columns_of_num은 숫자형 데이터들을 저장하고
-
columns_of_cat은 숫자형 데이터가 아닌 카테고리 변수들을 저장한다.
숫자형 데이터는 scaling이 필요하고, 카테고리 변수들은 전처리가 필요하기 때문

- 사용할 라이브러리를 import하고
- encode_cat에 OneHot encoding을 이용하여 encoding해준다.
- 카테고리 데이터들을 수치형 데이터로 변환해준다.
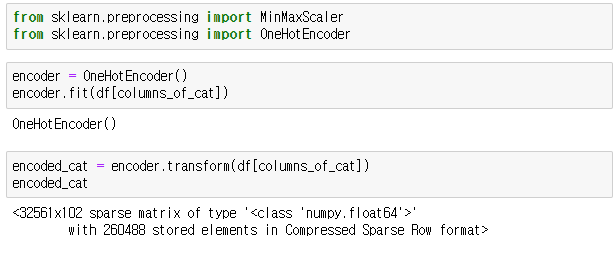
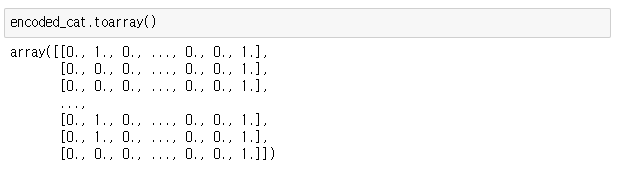
- encoding한 값들을 확인
- column당 고유값의 개수를 모두 계산하여 total_num에 저장한다.
-
그리고 수치화된 데이터를 가변수화 하여 나타내 준다.
수치형 데이터로만 변환을 하게 되면 실제로 없던 서로간의 관계성이 생기게 되므로
=> 사실이 아닌 관계성으로 인해 잘못된 학습이 일어날수 있다.
=> 따라서 더미로 만든 가변수로 변환함으로써 이러한 문제를 막아준다.
- pandas의 get_dummies 함수를 사용

- MinMaxScaler을 이용하여 숫자형 데이터들에 scaling
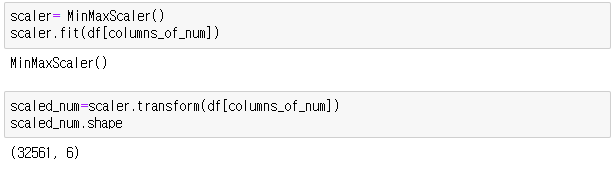
-
label에 따라 클래스를 나누어준다.
- error은 아니고 경고같은 느낌인데 직접 변경하려고 해서 그런거같다.
- 깊은 복사를 이용해서 복사한후 값을 변경하면 뜨지 않을거라 생각함
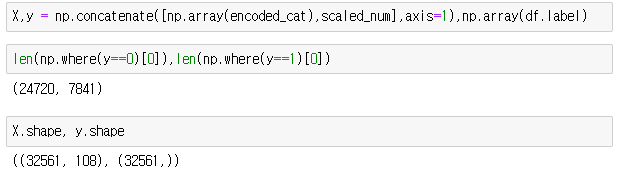
- np.concatenate() : 배열을 합치는 메소드
- 전처리를 한 카테고리 변수들 + 스케일링한 숫자형 변수들을 X에저장하고
- y에는 label값을 저장한다.
- => 학습데이터
KNeighborsClassifier [k-NN] + Evaluation

- 예측 결과가 82% 맞는다는 것을 확인할수 있다.
k-NN의 k 값을 변경하여 실습진행 후 k=7일 때, 결과 비교 및 분석
- k=7일때 예측 정확도 : 82%
- k=15일때 예측 정확도 : 83%
- k=21일때 예측 정확도 : 84%
- k=23일때 예측 정확도 : 82%
이를 보았을때 k값에 따라 예측 정확도가 변할수 있다는 것을 알수있다. 그리고 클래스 1,2를 예측 성공하는 확률도 변한다는 것을 알수있다. 이 실습에서는 처음에는 k값이 증가할수록 예측 정확도가 증가하고 21을 기준으로 더 늘어나면 오히려 정확도가 줄어드는 것을 확인할수 있었다.
이를 통하여 적절한 k값을 찾는것이 중요하다는 것을 알수있다.
수치형 변수에 Scaling 을 적용하지 않고 실습진행 후 결과 비교 및 분석
이 실습에서는 처음에 수치형 변수를 df.describe()을 통해 확인할수 있고, [‘C0’, ‘C2’, ‘C4’, ‘C10’, ‘C11’, ‘C12’]이 수치형 변수임을 확인할수 있었다.
그리고 이 수치형 데이터는 columns_of_num에 저장된 후 MinMaxScaler을 이용해 scaling 한후 scaled_num에 저장되어 scaled_num이 학습데이터를 준비하는데 사용된다.
그러므로 Scaling이 되지 않은 수치형 변수는 columns_of_num이라고 볼수있다.
따라서 수치형 변수에 Scaling 을 적용하지 않고 실습을 진행하기 위해 scaled_num을 사용하지 않고 columns_of_num을 사용하여 X,y를 만들어 주도록 하겠다.
# 전처리를 한 카테고리 변수들 + 스케일링한 숫자형 변수들을 X에저장하고 y에는 label값을 저장 => 학습 데이터 준비 + 확인
X,y = np.concatenate([np.array(encoded_cat),df[columns_of_num]],axis=1),np.array(df.label)
- KNeighborsClassifier k를 바꾸어서 진행한 결과
# KNeighborsClassifier을 k=7로 진행하고 결과를 확인해본다.
KNN = KNeighborsClassifier(n_neighbors=7)
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2)
y_train = y_train.astype('int')
KNN.fit(X_train,y_train)
pred_y=KNN.predict(X_test)
(pred_y==y_test).mean() , (pred_y[y_test==1]==1).mean() , (pred_y[y_test==0]==0).mean()
# (0.7916474742822048, 0.3049414824447334, 0.942110552763819)
# KNeighborsClassifier을 k=21로 진행하고 결과를 확인해본다.
KNN = KNeighborsClassifier(n_neighbors=7)
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2)
y_train = y_train.astype('int')
KNN.fit(X_train,y_train)
pred_y=KNN.predict(X_test)
(pred_y==y_test).mean() , (pred_y[y_test==1]==1).mean() , (pred_y[y_test==0]==0).mean()
#(0.7812068171349609, 0.2917189460476788, 0.9398251677170156)
Scaling을 하고 KNeighborsClassifier을 진행했을때
- k=7일때 예측 정확도 : 82%
- k=15일때 예측 정확도 : 83%
- k=21일때 예측 정확도 : 84%
Scaling을 하지 않고 KNeighborsClassifier을 진행했을때
- k=7일때 예측 정확도 : 79%
- k=21일때 예측 정확도 : 78%
이를 봤을때 Scaling을 하지 않은 경우가 Scaling한 경우보다 예측 정확도가 떨어지는 것을 확인할수 있다. Scaling이란 서로 다른 특성들을 일정한 값의 범위로 맞추어 주는 것이다. 그리고 Scaling에서 흔히 사용하는 방식이 Min-Max 스케일링과 정규화 방식이 있는데 여기에서는 sklearn에서 제공하는 MinMaxScaler을 사용하여 Min-Max 스케일링을 사용하였다.
따라서, 특성별로 데이터의 스케일이 다르다면 예측이 잘 동작하지 않기때문에, Scaling을 통해, 모든 특성의 범위(또는 분포)를 같게 만들어 주어야 한다.
- Scaling을 수행하지 않은 df[columns_of_num]은 그렇지 않지만
- scaled_num은 Scaling을 수행하여 전체 데이터가 모두 0~1 사이의 값으로 변환된 것을 알 수 있습니다.
#df[columns_of_num], scaled_num의 차이 확인
"df[columns_of_num]",df[columns_of_num], "scaled_num",scaled_num
